What a Modern Data Engine Does: The Technical Foundation Behind Clean, Actionable Operational Data
Most data quality problems are not analysis problems. They are pipeline problems. Here is what each layer of a modern data engine actually does.
TL;DR
Most data quality problems are not analysis problems. They are pipeline problems that get discovered during analysis. A modern data engine addresses data quality at its origin: the layers where data is ingested, classified, extracted, transformed, validated, and governed before it reaches any dashboard, model, or regulatory filing. This post explains what each of those layers does, why they matter, and what the decision looks like between building, buying, and running data infrastructure as a managed service.
"Forty-three percent of chief operations officers identify data quality as their most significant data priority", according to the IBM Institute for Business Value's 2025 research. The finding is consistent across industries. It is also slightly misleading about where the problem actually lives.
Data quality is not primarily a problem of analysis. It is a problem of pipeline design. By the time a data quality issue surfaces in a dashboard, a model output, or a regulatory report, it has typically traveled through several systems and influenced several decisions without anyone noticing. The issue originated much earlier, in how the data was ingested, classified, or validated before it reached the analysis layer. Organizations that approach data quality as an analysis problem spend considerable effort cleaning and correcting data after the fact. Organizations that approach it as a pipeline problem build the infrastructure to prevent bad data from propagating in the first place. The second approach produces fundamentally different outcomes at scale, and the gap between them widens as data volumes and AI dependence grow.
A 2026 analysis by Digna.ai citing SAP Fioneer research found that four of the Bank of England's top five perceived AI risks were data-related. Behind most significant enforcement actions in transaction monitoring, KYC, and sanctions screening is a data quality problem that was visible in source systems long before it was visible to the regulator.
Why Most Operational Data Is Unreliable Before It Is Even Analyzed
The gap between raw data and reliable operational data is wider than most organizations recognize until they try to close it. Data arrives from multiple sources, in different formats, on different schedules, with different conventions for representing the same concept. Without a structured pipeline to normalize it, every downstream consumer is working with data shaped by the limitations of its source system, not by the requirements of the decision it is supposed to support.
Ingestion problems
Data arrives from external feeds, internal systems, documents, APIs, and manual processes, often simultaneously. Each source has its own schema, naming conventions, update frequency, and error behavior. A financial data feed that fails silently does not announce its failure. It simply stops updating. A document that arrives with a scanned page instead of machine-readable text does not trigger an error. It produces a blank field in the extraction output. These are not edge cases. They are the normal behavior of real-world data sources at operational volume.
Transformation and classification problems
The same concept expressed differently across two source systems creates a mapping problem. Gross income on a tax return and gross revenue on a financial statement may refer to the same underlying figure or to different ones, depending on the entity structure. A pipeline that treats them as identical because the field names are similar will produce errors that are nearly impossible to detect without domain knowledge of the source documents.
Classification errors compound this problem. A document misclassified at ingestion carries that misclassification through every downstream step. An extraction model configured for financial statements applied to a tax return produces structured fields that look valid but represent the wrong data.
Validation gaps
Most data pipelines validate format: is this field a number, is this date parseable, is this string non-empty. Very few validate meaning: does this income figure reconcile with the one reported in the prior period, does this ownership percentage sum correctly with the other owners on file, does this transaction amount fall within the expected behavioral range for this account. Format validation catches structural errors. Meaning validation catches the errors that actually affect decisions.
What a Data Engine Actually Has to Do
A modern data engine is not a database or a reporting tool. It is the operational infrastructure that sits between raw data sources and the systems that consume clean, structured data. It handles the work that has to happen before analysis is possible. Each layer addresses a specific failure mode that, if left unaddressed, propagates errors downstream.
Layer 1: Ingestion and source monitoring
The first job is getting data from where it lives into a form the pipeline can process. This means connecting to source systems, receiving file transfers, processing document uploads, and pulling from external feeds. It also means monitoring each of those sources for failure modes that do not announce themselves: a feed that stops updating, a file that arrives in an unexpected format, a source system that begins returning null values where it previously returned populated fields.
Ingestion-layer monitoring produces a source health record for every data feed. When something changes, the pipeline flags it before it propagates to downstream consumers. Most organizations discover source failures when an analyst notices an anomaly in a report. A well-designed ingestion layer surfaces them before the data reaches any report.
Layer 2: Classification
Unstructured and semi-structured data has to be identified before it can be processed. A document arriving in an intake queue needs to be classified as a specific type before the correct extraction logic can be applied to it. A financial statement, a tax return, a bank statement, and a purchase agreement all require different extraction configurations. Applying the wrong configuration produces output that looks structurally correct but contains the wrong data.
Classification at scale uses AI-powered document understanding to identify document types by content rather than by filename or metadata. A document renamed to avoid detection, a form reformatted by a new issuer, or a document type the pipeline has not previously encountered: all of these are handled by a model that understands what a document is rather than what it is labeled as.
Layer 3: Extraction
Extraction is the process of pulling specific data fields from classified source material, whether that material is structured (a database record), semi-structured (a PDF form), or unstructured (a handwritten document or a narrative-format filing). The technical requirements differ substantially across these categories.
For structured sources, extraction is schema mapping. For semi-structured documents, it requires understanding where a field appears even when the layout varies across instances. For unstructured sources, it requires recognizing that a concept exists in the text before extracting its value. A data engine that handles all three without manual pre-processing for each new document variant is doing substantial work that most organizations have not built the infrastructure to support.
Languages present an additional layer of complexity. A data pipeline handling documents from international counterparties needs extraction capability across the languages those documents arrive in, with translation applied to structured output fields rather than to the raw document. Forty-plus language coverage is the practical threshold for organizations operating at meaningful international scale.
Layer 4: Transformation and normalization
Extracted data from different sources has to be normalized before it can be used together. Dates formatted differently across systems. Currency figures in different denominations. Entity names with minor variations across sources. Calculated fields derived from multiple inputs. Normalization converts source-specific representations into a consistent schema that downstream consumers can rely on.
This layer also handles the reconciliation logic that connects related fields across documents. When the same figure appears in multiple source documents, the pipeline maps those instances to each other and surfaces discrepancies for review rather than silently propagating one version and ignoring the other.
Layer 5: Validation and exception handling
Validation is where the pipeline asks whether extracted and transformed data is consistent, complete, and within expected parameters. Format validation is the minimum. A modern data engine also performs cross-document validation (does this figure reconcile across the three sources that should report the same value), range validation (does this figure fall within the expected range for this entity type and period), and completeness validation (are all required fields present and populated).
Items that fail validation do not pass silently to downstream systems. They route to a human-in-the-loop layer where a reviewer sees the source data, the extracted value, the specific validation failure, and contextual information that supports a resolution decision. The reviewer's decision is logged and feeds back into the pipeline as a correction record and, where applicable, as training signal for future classification and extraction.
Layer 6: Governed delivery
Clean, validated data has to reach the systems that consume it: core platforms, analytics tools, regulatory reporting systems, AI models, executive dashboards. Governed delivery means data is delivered in the format each consuming system requires, on the schedule those systems depend on, with access controls that limit which systems and users can access which data elements.
Governed delivery also means that every step from source to delivery is logged. What was received, when, from what source. How it was classified, extracted, transformed, validated. What exceptions were identified and how they were resolved. What was delivered, when, to which consuming system. This end-to-end record is the audit trail that makes the pipeline defensible to regulators, auditors, and operational reviewers.
Governance and Lineage: Knowing Where Every Data Point Came From
Data lineage is the capability to trace any data point in any downstream system back to its source, including every transformation and validation step in between. For financial services organizations, this is not a technical nicety. It is a regulatory expectation. When an examiner or auditor asks where a figure in a regulatory filing came from, the answer has to be specific, complete, and immediately retrievable. For a detailed treatment of why this matters in financial services specifically, see the post on data lineage in financial services.
A data engine that produces lineage as a byproduct of normal operation is structurally different from one that requires manual documentation of data flows. Manual lineage documentation is a snapshot of how the pipeline worked at the moment it was written. It becomes stale as the pipeline evolves. Automated lineage is a continuous record of how the pipeline actually operates, updated with every run.
Lineage also enables impact analysis. When a source data problem is identified, the question is not just what went wrong but what downstream systems and outputs were affected. A pipeline with complete lineage can answer that question immediately. A pipeline without it requires a manual audit that may take days and may still not be complete.
Continuous Monitoring and Operational Visibility
A data engine that runs reliably until it fails silently is not operationally useful. Operational visibility means knowing, in near real time, the status of every data feed, every processing queue, every exception item, and every delivery. It means surfacing anomalies before they affect downstream consumers, not after.
Effective monitoring operates at multiple levels: source health (is each feed delivering as expected), processing health (are classification and extraction performing within expected accuracy parameters), exception health (are exception queues clearing within defined SLAs), and delivery health (did each consuming system receive its expected data on schedule).
Executive dashboards aggregate this visibility into the operational indicators that matter to non-technical stakeholders: data freshness by source, exception resolution rates, SLA compliance by workflow, and trend data that shows whether pipeline health is improving or deteriorating over time.
Common Use Cases
The same underlying data engine capabilities apply across different operational contexts. The specific configuration changes. The architecture does not.
Document-intensive onboarding workflows: classification and extraction handle the document processing, validation confirms completeness and consistency, exception routing surfaces items requiring compliance judgment, governed delivery populates the core system or CRM.
Daily reconciliation: ingestion pulls transaction files from multiple systems, transformation applies matching logic, validation identifies exceptions and near-matches, governed delivery produces the day's reconciled ledger with exception queue populated for human review.
Regulatory reporting: ingestion aggregates data from source systems on defined schedules, transformation applies reporting-period logic and entity consolidation, validation confirms data completeness against filing requirements, governed delivery produces the submission-ready dataset.
Vendor and counterparty monitoring: ingestion pulls from external data sources including web scraping of public filings and regulatory databases, classification and extraction identify relevant data elements, validation cross-references against internal records, governed delivery surfaces changes requiring review.
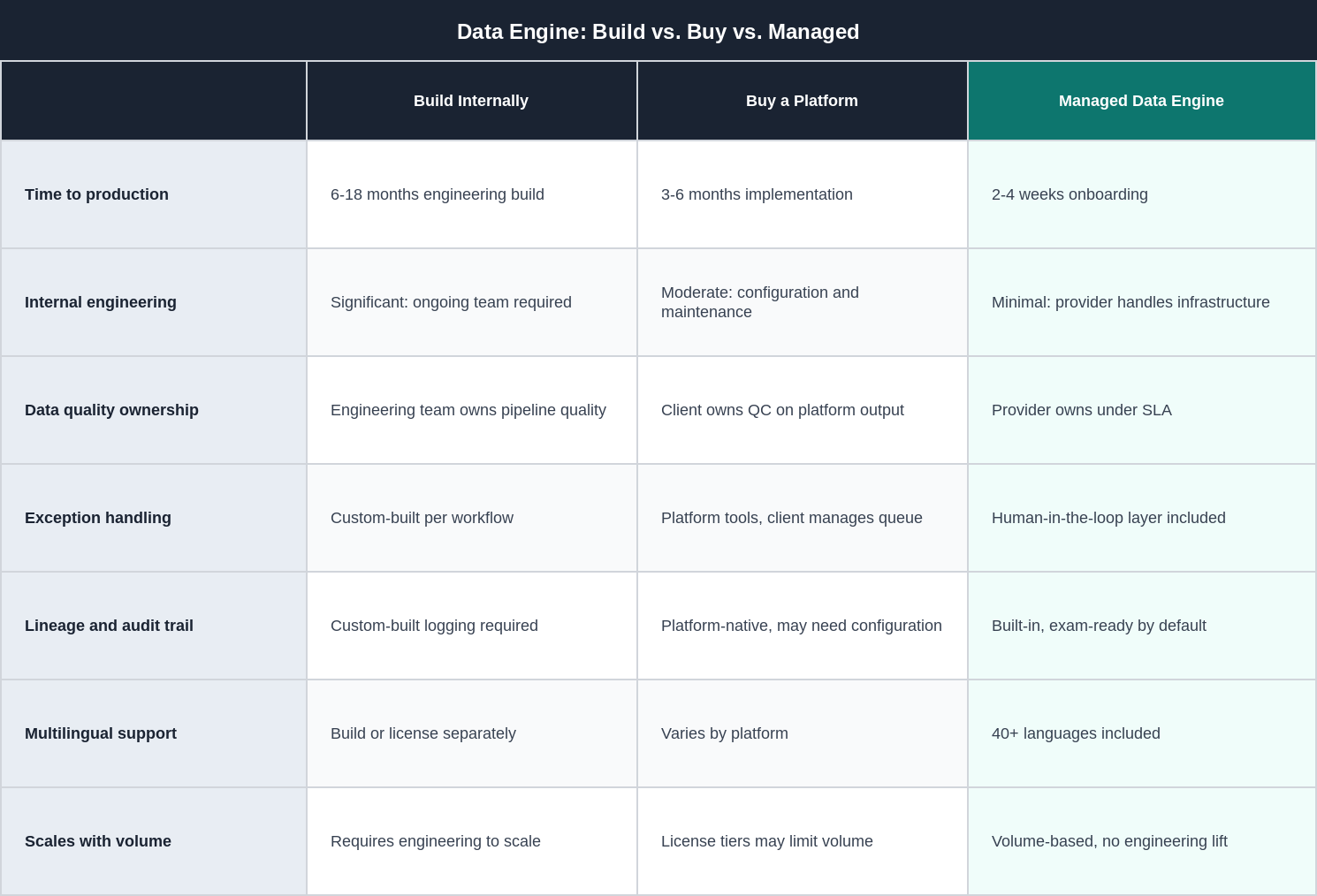
Build vs. Buy vs. Managed Data Engine
Frequently Asked Questions
What is the difference between a data pipeline and a data engine?
A data pipeline is the infrastructure that moves data from source to destination. A data engine is a broader term for the complete operational system that governs data from ingestion through governed delivery, including classification, extraction, transformation, validation, exception handling, lineage, and monitoring. Every data engine contains pipelines. Not every pipeline is a data engine. The distinction matters when evaluating whether an organization's data infrastructure addresses quality at the origin or simply moves data faster.
How does a data engine handle documents that don't follow a standard format?
A well-designed data engine uses AI-powered classification to identify document types by content rather than by format or layout. When a new document variant arrives (a form reformatted by a new issuer, a document type not previously seen), the classification model identifies it based on semantic content rather than structural pattern matching. Items with low classification confidence route to the human-in-the-loop layer for manual classification, and that manual decision becomes a training signal that improves future classification accuracy.
What does multilingual support actually require at the pipeline level?
Supporting multiple languages in a data pipeline requires language-aware classification (identifying what a document is in any supported language), language-specific extraction models (understanding the field structure and terminology conventions in each language), and translation of extracted structured fields into a normalized output schema. The translation layer applies to specific data fields in the structured output, not to the raw document, which means the translation quality required is for defined field types rather than for narrative text.
How is a managed data engine different from a data analytics outsourcing engagement?
A data analytics engagement typically provides analytical outputs: reports, models, dashboards, insights. A managed data engine provides operational data infrastructure: the clean, structured, validated data that analytics, AI models, and operational systems depend on. They address different parts of the value chain. An organization that outsources analytics without addressing pipeline quality is building analysis on an unreliable foundation. The managed data engine is the foundation layer, not the analysis layer.
What does auto-reconciliation mean in a data engine context?
Auto-reconciliation is the pipeline's capability to match related data elements across multiple source systems and confirm or flag their consistency without manual intervention. In a daily reconciliation workflow, auto-reconciliation matches transaction records across the source systems that should reflect the same event, flags near-matches for human review, and produces a reconciled ledger with exceptions pre-categorized and contextual information assembled for each exception item.
Shore Group runs managed data infrastructure for operations teams
Document intelligence, multilingual extraction, auto-reconciliation, data lineage, exception handling, and executive dashboards. We own the data quality. You consume the output.
See Our Digital Solutions